
“能不能用ChatGPT批量生成英文內(nèi)容,獲取谷歌自然搜索流量呢?“這是我最近聽(tīng)到業(yè)內(nèi)大家最多的討論,我的答案是:去年肯定可以,今年可能可以。為什么這么說(shuō)?用Semrush看3個(gè)網(wǎng)站數(shù)據(jù): 

牛,自然流量從0到巔峰,基本只花了6個(gè)多月的時(shí)間,單單一句“臥槽”,都不足以形容去年3月份我剛剛發(fā)現(xiàn)的情緒。而且,這幾個(gè)網(wǎng)站大概率是一位老哥的,網(wǎng)站采取了幾乎一致的網(wǎng)站架構(gòu)和選題策略,我沒(méi)有一一進(jìn)行比對(duì),但粗略的看,前兩個(gè)站可能有8成的文章采用了相同的標(biāo)題,相同的內(nèi)容生成策略,文章表達(dá)則不同。從SEO知識(shí)角度的來(lái)講,可以說(shuō),這位老哥選了上萬(wàn)個(gè)超低競(jìng)爭(zhēng)度(沒(méi)人寫(xiě)但是有少量人搜索)的長(zhǎng)尾詞去創(chuàng)作內(nèi)容,滿(mǎn)足所謂的搜索意圖。千萬(wàn)級(jí)谷歌月自然搜索流量,掛上廣告聯(lián)盟,妥妥的日賺斗金。打開(kāi)網(wǎng)站,就長(zhǎng)下面這個(gè)樣子,數(shù)千篇“問(wèn)號(hào)”文章,我當(dāng)時(shí)也是一頭問(wèn)號(hào),“知乎?Quora?”
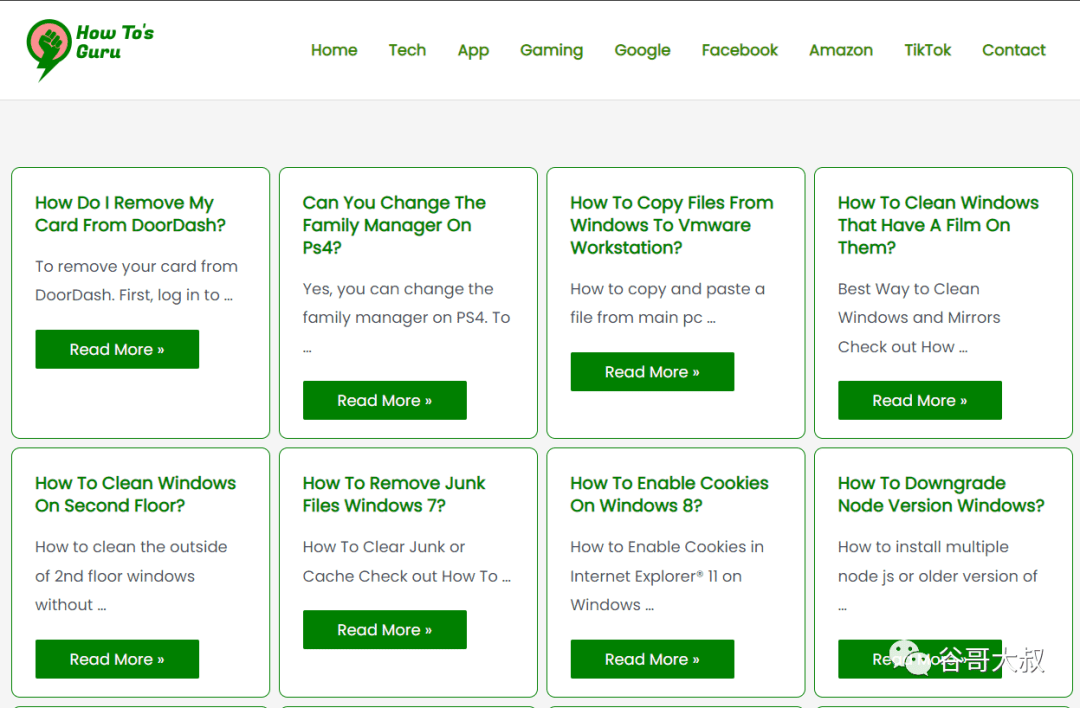
隨機(jī)點(diǎn)開(kāi)一篇,好長(zhǎng),近2000字,部分截圖如下:
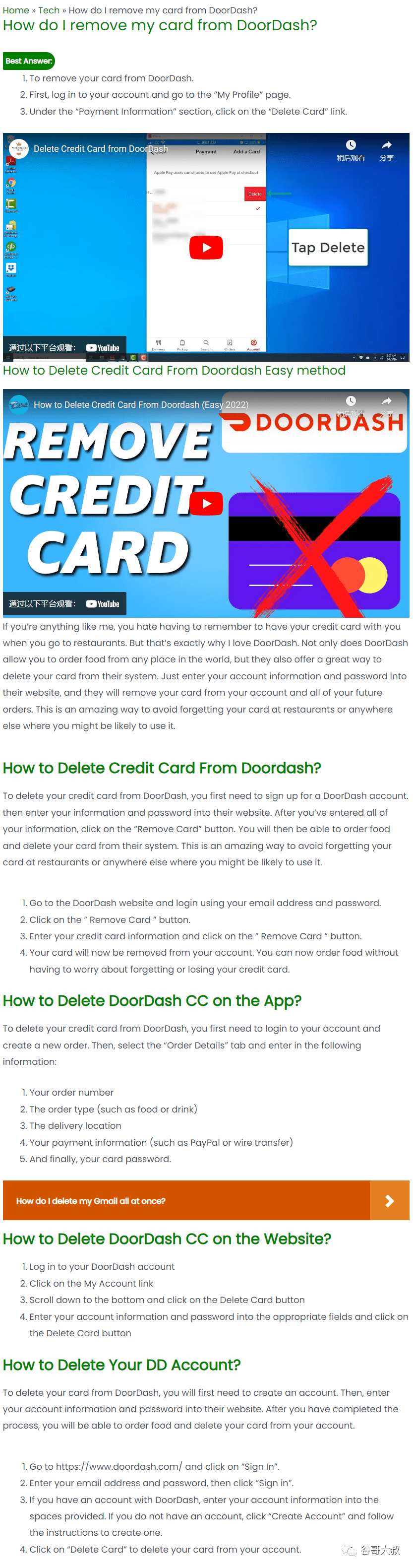
這么簡(jiǎn)單一個(gè)問(wèn)題,生生湊出來(lái)1500+字,不,是整個(gè)網(wǎng)站數(shù)千問(wèn)答全部超過(guò)了1500+字,有點(diǎn)東西。
第一感覺(jué)就是AI生成或爬蟲(chóng)抓的,既然是內(nèi)容生產(chǎn)成本很低的,能搞1個(gè),肯定會(huì)搞1堆。當(dāng)你復(fù)制“How do I remove my card from DoorDash?”等等長(zhǎng)尾詞去谷歌里面搜索,你會(huì)發(fā)現(xiàn)一堆類(lèi)似的網(wǎng)站,點(diǎn)開(kāi)之后,嗯,像是一個(gè)媽生的。

不僅像是一個(gè)媽生的,而且好像還是同一年生的,2021年,離譜。
爬蟲(chóng)扒別人內(nèi)容,用一些替換近義詞,修改語(yǔ)序的工具,幾套翻譯系統(tǒng)來(lái)回倒騰,偽原創(chuàng)改改上量,做谷歌SEO可行?不是這套玩法早就爛掉了嗎,怎么又死灰復(fù)燃了?
我一頭問(wèn)號(hào),于是在谷歌里探索性的搜了“AI文案”等關(guān)鍵詞,發(fā)現(xiàn)了一些新的AI工具,都自稱(chēng)使用的“GPT-3”算法,這是我第一次知道這個(gè)怪異的名詞,這個(gè)時(shí)期也是國(guó)外jasperAI(調(diào)用GPT-3的API的文案生成工具)高速發(fā)展時(shí)期,同時(shí)也是我自己受害的時(shí)期,這個(gè)一會(huì)講。
當(dāng)時(shí),我基本確定了這些網(wǎng)站肯定是使用了GTP-3相關(guān)的技術(shù),但是否使用的jasperAI,不確定,因?yàn)橛胘asperai的話(huà),成本還是挺高的,也可能是直接調(diào)用了GTP-3的API,站長(zhǎng)本身有開(kāi)發(fā)能力。
現(xiàn)在,打開(kāi)ChatGPT,如何生成一篇類(lèi)似的湊足2000字的HOW-TO文章呢?
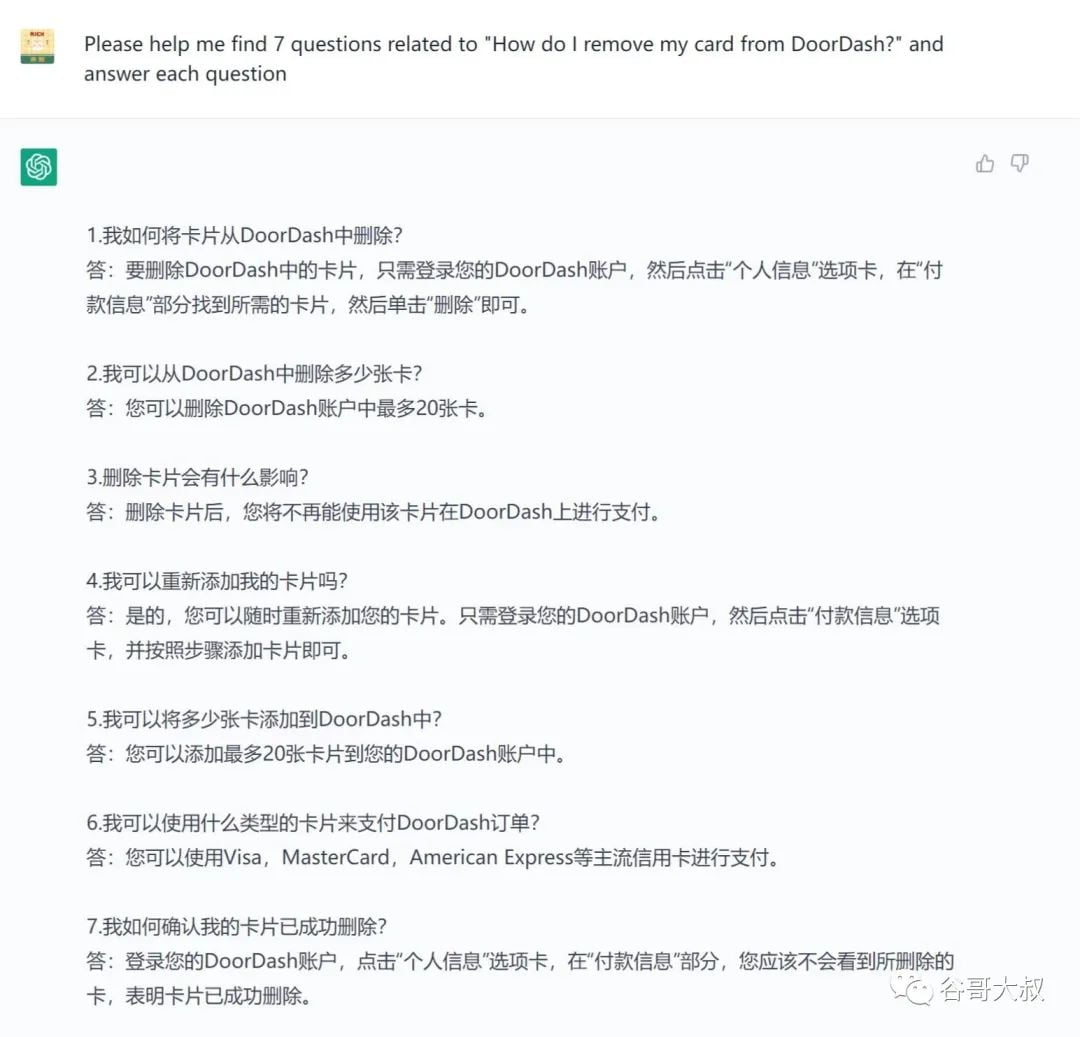
是不是跟開(kāi)頭那篇文章截圖很像?
來(lái),換個(gè)話(huà)題:

客觀(guān)說(shuō)還不錯(cuò),在湊字?jǐn)?shù)上,以及布局相關(guān)關(guān)鍵詞上一絕。語(yǔ)法用grammarly(語(yǔ)言檢查工具)檢測(cè)問(wèn)題不大,原創(chuàng)性用copyscape.com(類(lèi)似論文查重工具)檢查也過(guò)關(guān)。
“牛逼,chatgtp牛逼,沖,英文站群沖一波!”
等等,別急,去年年中我也是這么想的,還沒(méi)開(kāi)始搞,這批站就萎了。放一張圖吧,基本全軍覆沒(méi),漏網(wǎng)之魚(yú)有,你自己找找。
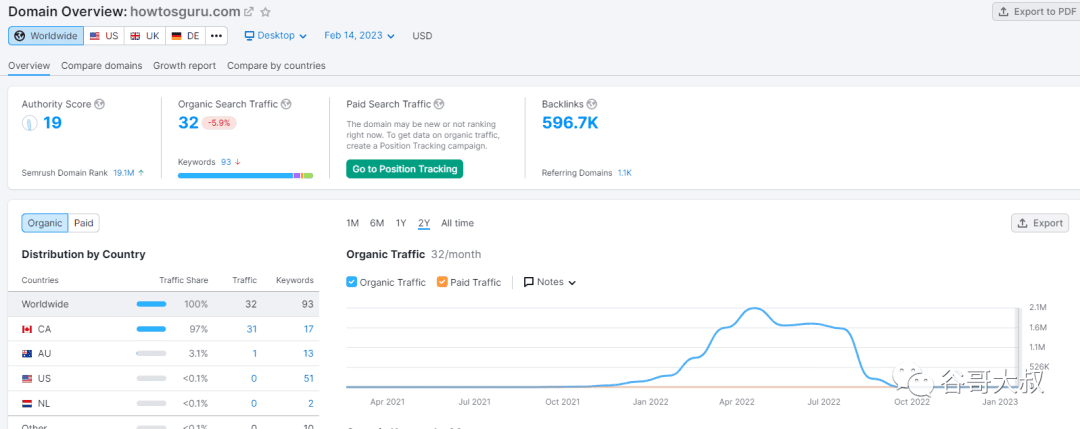
對(duì)了,你現(xiàn)在打開(kāi)上面這個(gè)網(wǎng)站,域名尾綴從“.com”變成了".info",也就是說(shuō),這位站長(zhǎng)意識(shí)到網(wǎng)站被谷歌判了死刑,想換個(gè)皮茍活。
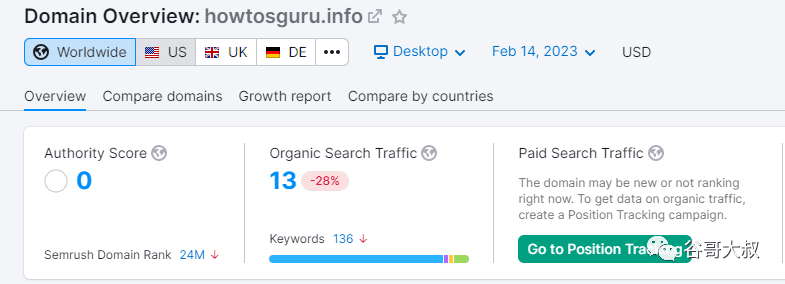
看來(lái)沒(méi)能如愿。
那怎么用chatgpt做谷歌SEO賺錢(qián),涼涼?
確切的答案我不知道,但可以提供2個(gè)我在研究的思路。
第一個(gè)思路:重新定義下問(wèn)題。
把“那怎么用chatgpt做谷歌SEO流量賺錢(qián)"這個(gè)問(wèn)題,改成"怎么用chatgpt在知乎/Quora/Instagram/Tiktok等有搜索框的且沒(méi)有AI內(nèi)容檢測(cè)能力的內(nèi)容平臺(tái)做SEO流量賺錢(qián)?
這個(gè)我想不需要詳細(xì)展開(kāi),大家知道怎么做。
第二個(gè)思路:研究谷歌識(shí)別AI生成內(nèi)容的判定標(biāo)準(zhǔn),逆向使用這些標(biāo)準(zhǔn)。
思考如何避免被谷歌檢測(cè)出內(nèi)容是AI生成的,先要知道他識(shí)別AI內(nèi)容的幾個(gè)可能的判定標(biāo)準(zhǔn)。谷歌下“Check Written AI GPT-3"等相關(guān)詞,可以找到很多內(nèi)容檢測(cè)工具,號(hào)稱(chēng)可識(shí)別文章是否由GPT-3為基礎(chǔ)的chatgpt或者jasperai 生成,比如originality.ai。
準(zhǔn)不準(zhǔn)呢?把前面列出的那批網(wǎng)站放進(jìn)去檢測(cè),大部分頁(yè)面會(huì)得到一個(gè)"100%"的回答,也就是說(shuō)被originality.ai判定這篇內(nèi)容有100%的概率是由AI生成的。
我又檢測(cè)了一批基本上主管判斷100%確定人工寫(xiě)作的文章,部分是我自己的網(wǎng)站內(nèi)容,部分是像紐約時(shí)報(bào)這樣的大站點(diǎn),被判定為AI生成的概率都在20%以?xún)?nèi)。


那么至少說(shuō)明這個(gè)工具還是比較靠譜。
傷心的時(shí)候到了。
考慮到我自己其中1個(gè)網(wǎng)站排名從去年末開(kāi)始流量下滑5成,一直找不到具體原因,前幾天對(duì)全站的所有文章進(jìn)行了檢測(cè),發(fā)現(xiàn)有大量的文章被originality.ai判斷8成概率是AI生成,看來(lái)是被谷歌懲罰了。
大意了,被割了一刀,之前只注意內(nèi)容質(zhì)量,原創(chuàng)性語(yǔ)法等指標(biāo),為了省錢(qián),把很多簡(jiǎn)單的信息類(lèi)通過(guò)fiverr和upwork等平臺(tái)外包給印度人寫(xiě)作, 現(xiàn)在看來(lái),他們是用了jasperai等工具生成的。
翻看下這類(lèi)似originality.ai的AI內(nèi)容檢測(cè)工具的原理介紹,可以大概推測(cè)出3個(gè)谷歌可能使用的判定標(biāo)準(zhǔn),以及避免被谷歌識(shí)別出內(nèi)容是AI生成3個(gè)標(biāo)準(zhǔn)逆用方向。
如果文章中有大量相似單詞和短語(yǔ)的重復(fù),則更容易被判斷為AI生成。
這一點(diǎn)比較容易理解,如果你使用過(guò)chatgpt就可以感受到:?jiǎn)査粋€(gè)非常簡(jiǎn)單的問(wèn)題,一般人可能用100字回答,但是要求chatgpt使用1000字來(lái)回答,那么它會(huì)在答案里大量充水,回復(fù)文本表現(xiàn)出大量意思相似語(yǔ)句重復(fù)的特點(diǎn),車(chē)轱轆話(huà)。
標(biāo)準(zhǔn)逆用方向:盡量的避免像下面這個(gè)網(wǎng)站一樣,為了湊字?jǐn)?shù),使用相關(guān)關(guān)鍵詞拼湊的方式,強(qiáng)行對(duì)內(nèi)容充水,直接使用AI生成問(wèn)答型內(nèi)容獲取長(zhǎng)尾流量這種做法現(xiàn)在已經(jīng)走不通了。
如果文章中單詞的分布概率與檢測(cè)工具調(diào)用GTP-3的API接口生成的文本,相似度高,則更容易被判定為AI生成。
這段話(huà)比較繞,我復(fù)制一下英文原文的解釋?zhuān)涸诮o定左側(cè)上下文的情況下,根據(jù)每個(gè)詞成為預(yù)測(cè)詞的可能性來(lái)分析每個(gè)詞。如果單詞在前 10 個(gè)預(yù)測(cè)單詞中,背景顏色為綠色,對(duì)于前 100 個(gè)單詞,背景顏色為黃色,前 1000 個(gè)單詞為紅色,否則為紫色。如果您看到充滿(mǎn)大量綠色的內(nèi)容,則很可能是由 AI 生成的。

標(biāo)準(zhǔn)逆用方向:避免直接利用chatgpt直接根據(jù)一個(gè)主題生成內(nèi)容,而是自己提供文章的細(xì)致的大綱,然后讓chatgpt在這個(gè)大綱的基礎(chǔ)上生成內(nèi)容,前提要保證:你提供的大綱與你讓chatgpt直接根據(jù)文章主題生成的大綱有比較大的差異,也就是寫(xiě)作的角度要不同。
如果內(nèi)容中包含了大量短問(wèn)短答,缺少?gòu)?fù)雜長(zhǎng)句,則更加容易被判定為AI生成。
這一點(diǎn)為什么我本身還沒(méi)想清楚,可能是因?yàn)閺?fù)雜的長(zhǎng)句邏輯過(guò)于復(fù)雜,chatgpt比較難以駕馭。
標(biāo)準(zhǔn)逆用方向:如果你想在頁(yè)面布局通過(guò)布局問(wèn)題的形式,把大量的相關(guān)詞塞進(jìn)去,那么我建議你,在使用chatgpt生成內(nèi)容的時(shí)候,把多用長(zhǎng)句作為一個(gè)要求寫(xiě)進(jìn)?prompt (對(duì)答提示) 中。

當(dāng)然,如果你覺(jué)得以上這些點(diǎn)都太啰嗦,那么你可以考慮使用chatgpt生成內(nèi)容后,在使用Quillbot/WordAI?/jasperai等類(lèi)似的AI內(nèi)容生成工具,對(duì)文本進(jìn)行潤(rùn)色和修改。
我自己經(jīng)過(guò)小樣本測(cè)試,發(fā)現(xiàn)如果在使用chatgpt生成的內(nèi)容的基礎(chǔ)上,再使用一個(gè)AI文本工具進(jìn)行二次處理,那么處理后的文本使用originality.ai 檢測(cè)的時(shí)候,被判定為AI生成的概率大大降低,但是,我要說(shuō)一句,這并不代表谷歌識(shí)別不出。
關(guān)于chatgpt與SEO這個(gè)話(huà)題,還有很多值得討論的問(wèn)題,比如:
chatgpt生成的內(nèi)容,不符合SEO標(biāo)準(zhǔn),那么如何在流程上優(yōu)化,可以一開(kāi)始就生成符合SEO標(biāo)準(zhǔn)的內(nèi)容?
chatgpt只有一個(gè)對(duì)話(huà)框,太過(guò)于自由了,如何寫(xiě)提示prompt 才能更大限度的發(fā)揮chatgpt的能力來(lái)產(chǎn)出?
作者:石三張@黃聰? 來(lái)源:石三張@黃聰?
本文為作者獨(dú)立觀(guān)點(diǎn),不代表出海筆記立場(chǎng),如若轉(zhuǎn)載請(qǐng)聯(lián)系原作者。

